Assembly |
 |
Computer Organization and Assembly Languages, Fall 2006
|
Jump to...
assignment #1
|
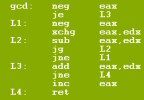
Assignment #5: Matrix MultiplicationAssigned: 12/11/2006Due: 12/27/2006 11:59pm Skeleton code was update at 9:30pm on 12/19. Or, you can just download the updated main.c. DescriptionIn this project, you have chance to practice FPU programming. The application we choose is matrix multiplcation. Matrix multiplication is an important operation in numeric methods. Given two matrices A and B whose sizes are mxn and nxl respectively, their product C=AXB is defined as the following where C is a mxl matrix. Refer to wikipedia for more information. The basic algorithm for matrix multiplication is shown below. Its complexity is roughly O(n^3).
void ijk(array A, array B, array C, int m, int n, int l)
{
int i, j, k;
for (i = 0; i < m; ++i)
for (j = 0; j < l; ++j) {
C[i][j] = 0;
for (k = 0; k < n; ++k) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
There are more
efficient algorithms such as Strassen's algorithm and Coopersmith's
algorithm. Please refer to
wikipedia
if you are intereted in these.
However, it is not recommended to implement these algorithms in assembly.
On the other hand, a useful way to speed up your program is to improve
data coherence of your code.
Because of better cache coherence, it could run faster.
As explained in the class, you could choose an appropriate
loop order so that the loop body is more coherent.
A more efficient way to improve cache coherence is to reconfigure your matrices as blocked matrices. The following pseudo code shows blocked matrix multiplication for square matrices.
void bijk(array A, array B, array C, int n, int bsize)
{
int i, j, k, kk, jj;
double sum;
int en = bsize*(n/bsize); // amount that fits evenly into blocks
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
C[i][j] = 0.0;
for (kk = 0; kk < en; kk += bsize) {
for (jj = 0; jj < en; jj += bsize) {
for (i = 0; i < n; i++) {
for (j = jj; j < jj+bsize; j++) { // updated 2006/12/19
sum = C[i][j];
for (k = kk; k < kk+bsize; k++) {
sum += A[i][k]*B[k][j];
}
C[i][j] = sum;
}
}
}
}
}
The only thing remaining is to figure out an appropriate block size, bsize,
in the above code. It is reported that bsize=25 works well for Pentium III
CPU.
For more details, please refer to chapter 6 of
the CS:APP book.
Be aware that this algorithm requires significant efforts to make it work.
Unless you are extremely motivated, I do not encourage you to try it.
It is, however, an excellent topic for your final project though.
SpecificationYou have to implement a procedure called "mul" in assembly. This procedure accepts six parameters, three pointers to float-point arrays for the matrices A, B and C, three integers for the dimensions of these arrays, m, n and l. The skeleton looks like
.686
.model flat
option casemap :none
.xmm ; for SIMD instructions
; tell assembler these are external C procedures.
EXTERN C malloc: proc
EXTERN C free: proc
.data
tmp DWORD 0
.code
_mul PROC PUBLIC
push ebp
mov ebp, esp ; build stack frame
; variables in stack
; [ebp+28] l (the 6th argument)
; [ebp+24] n (the 5th argument)
; [ebp+20] m (the 4th argument)
; [ebp+16] pointer to C (the 3rd argument)
; [ebp+12] pointer to B (the 2nd argument)
; [ebp+8] pointer to A (the 1st argument)
; [ebp+4] return address
; [ebp] previous ebp
; A: m rows by n columns ( m*n*sizeof(float) = 4*m*n bytes )
; B: n rows by l columns ( n*l*sizeof(float) = 4*n*l bytes )
; C: m rows by l columns ( m*l*sizeof(float) = 4*m*l bytes )
; Note:
; Our submission system:
; - Pentium3 1 Ghz with 256KB L2 cache
; - MMX and SSE supported
;
; My laptop (might be the re-judge system):
; - Mobile Pentium3 1.2 Ghz with 512KB L2 cache
; - MMX and SSE supported
;
; Please do not use SSE2/SSE3/3D Now!/3D Now! 2 instructions,
; our processors doesn't support them. :-)
; begin C = A * B operation
; WRITE YOUR OWN CODE HERE
; end C = A * B operation
leave
ret
_mul ENDP
END ; file ends here
In hw5.zip, you will find main.cpp where other
functions are implemented. They are used to generate matrices and do timing.
You don't need to modify this file. A project file is included so that
you can build and debug your program directly in MSVC++ 2005.
Note that you have to specify arguments m, n and l to tell th program the dimensions of matrices. In MSCV++ 2005, you could specify arguments in project's properties. Click the "hw5" directory in the solution explorer using right mouse button. Click the last item, "Properties," in the popup menu. Click on the "Debugging" option under "Configuration Properties." Fill in arguments such as "20 10 15" in the "Command Arguments" colume of the right panel. Once you have specified the arguments, the program automatically generates random matrices and verify whether your result is correct. GradingAs always, you will get 80 points if you implement this procedure correctly. Another 0~25 points will be added to your grade depends on the speed of your program and 0~5 points depends on the code size.SubmissionAs usual, submit your homework through the online submission system. The entry for hw#5 will be open shortly. |
|||||||

|

|
|||||||