|
Linear Relational Embedding
 Preface Preface
在這裡我們要介紹由Alberto
Paccanaro 及 G. E. Hinton
所提出的Linear Relational Embedding (LRE) 概念. 我們主要參考的paper有:
A. Paccanaro
Learning Distributed Representations of Concepts from Relational Data
ICML 2002, Workshop on Development of Representations, E. de Jong and T. Oates,
eds.
A. Paccanaro, G. E. Hinton
Learning Hierarchical Structures with Linear Relational Embedding NIPS 14,
Advances in Neural Information Processing Systems 14, T. G. Dietterich and S.
Becker and Z. Ghahramani eds., 2001
A. Paccanaro, G. E. Hinton
Learning Distributed Representations of Relational data using Linear Relational
Embedding
Proceedings of the 12-th Italian Workshop on Neural Nets, WIRN VIETRI, 2001
A. Paccanaro, G. E. Hinton
Learning Distributed Representation of Concepts using Linear Relational
Embedding IEEE Trans. on Knowledge and Data Engineering - special issue on
'Connectionists Models for Learning in Structured Domains' Vol. 13, N.2,
March/April 2001, 232-245
A. Paccanaro, G. E. Hinton
Learning Distributed Representation of Concepts using Linear Relational
Embedding
Gatsby Computational Neuroscience Unit - Technical Report 2000-002
A. Paccanaro, G. E. Hinton
Learning Distributed Representations by Mapping Concepts and Relations into a
Linear Space
ICML2000, Proceedings of the Seventeenth International Conference on Machine
Learning, Langley P. (Ed.), 711-718, Stanford University, Morgan Kaufmann
Publishers, San Francisco
A. Paccanaro, G. E. Hinton
Extracting Distributed Representations of Concepts and Relations from Positive
and Negative Propositions IJCNN 2000, Proceedings of the International Joint
Conference on Neural Networks
 What
is LRE What
is LRE
LRE
的主要想法就是希望能藉由已知的部分關聯資料來推斷出整體的關係架構,舉例來說,我們知道某一個家族的部分親屬資料(A是B的爸爸,C是D的叔叔...等等),但是我們並不知道這個家族的完整架構(家庭樹,
family tree),那麼,藉由LRE的方式就可以推斷出此家庭的完整家庭樹.
在介紹LRE的方法之前,我們必須先認識一些它的詞彙,我們就用家庭樹這個例子來了解這些詞彙的清楚概念.
instance: 一個描述關係的事實,如: Alex 是 Bob 的爸爸
concept:如 Alex, Bob, 表示個體
relation: 如 "...是...爸爸", 代表一種關係
triplet: 將instance改寫成作者定義的triplet形式: (concept1,
relationa, concept2),如"Bob的爸爸是Alex"這件事的triplet就是(Bob,
爸爸, Alex).
此外,作者用Euclidean space 中的向量來表示concepts; 用矩陣(線性運算)來表示relations,
這種運算方式也是LRE名稱的由來.
Method
LRE是藉由concepts所帶有的特徵(features)來推出整體的關係,舉例來說,"has
mother"這個關係建立了某一個人(X)和另一個人(Y)的關聯,並且,Y的features要是"年長X一代"且是"女性".因此當我們知道每一個concept的features及這些features是如何互動的規則時,我們就能推斷出新的instances.
假設我們已知的資料中有C個triplet, N個concepts,
與M種關係, 則每一個concept可以寫成n維的向量(V),且每一種關係可以寫成
(n*n) 的矩陣 (R). 今日,若我們欲找出一個concept c,其中a
與b的關係是R, 則我們實際上要求的就是希望R*a的值(noise
version )能近似b.
要達到這個趨近的目的,就必須滿足下列的方程式:
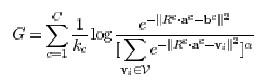
其中,c表示某一concept; 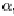 是一個約在0~1之間的數,且它的值並不影響實驗的結果; 而kc表示在我們的資料中,與concept
c的前兩項相同但與第三項不同的concepts數目(也就表示存在one-to-many的關係),
例如,目前的concept c 是(Alex, son, Bob), 且我們的資料中有:
(Alex, son, John), (Alex, son, Tom), (Alex, son, Mark), 則此kc=3.
是一個約在0~1之間的數,且它的值並不影響實驗的結果; 而kc表示在我們的資料中,與concept
c的前兩項相同但與第三項不同的concepts數目(也就表示存在one-to-many的關係),
例如,目前的concept c 是(Alex, son, Bob), 且我們的資料中有:
(Alex, son, John), (Alex, son, Tom), (Alex, son, Mark), 則此kc=3.
然而,這個方程式還有一個漏洞沒有解決,也就是推斷整體架構時,可能會遇到don't
know的情況,例如,在下面的家庭樹中:
我們可以用G建立這個家庭樹的架構並斷定(Arthur,
father, Christopher)這種complete concept, 但是卻無法找出(Christopher,
father, ?) 的concept, 這就是所謂uncomplete 的情形. 因此,為了要考慮到此類的情形,作者將
probabilistic model 的概念加到方程式G中,成了下列的形式:
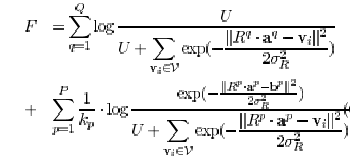
其中,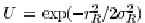 , 也就是Uniform
distribution 下的relative density, 回答了don't know 的問題. , 也就是Uniform
distribution 下的relative density, 回答了don't know 的問題.
Learning
Procedure
第一步,先使用僅含complete triplets 的 training set 來training
G中的向量和矩陣,使G值為最大,而作者採用的方式是 conjugate
gradient.
第二步,用validation set 來 training F, 且用simple
steepest descent的方式來做training. (註. validation set 中包括complete
triplets 和 uncomplete triplets,
並且每一種關係都要在兩類的triplets中至少個別出現一次.)
Any questions, please contact with cyliou@csie.ntu.edu.tw

All Rights Reserved by Cheng-Yuan, Liou,
Department of Computer Science and Information Engineering,
National Taiwan University.
|
|