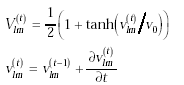

|
|
|
|
在手寫字辨識進階理論的部分,我們將特別介紹:1.紀錄手寫字特徵的bended ellipse features, 2.classification 中的比對方式,與 3.整個network training 的過程.
Bended ellipse features (J.13) 還記得我們在Introduction中曾介紹我們紀錄"字"的哪些特徵嗎?
沒錯,就是 像"口"這樣的字,每一個頂點(seed)都有兩個相連的邊,對於這樣的seed而言,它有
1 個feature vector; 而像"田"這個字中間這一點(seed),總共有四個邊與它相連,因此它有
6 個feature vectors(左與上,左與右,左與下,右與上,右與下,上與下),所以,計算feature
vector數目的方式就是
Compatibility (J.13) 在比對的過程中,我們會將手寫字及標準字與每一個字根做比對.
例如對於第j個字根Rj而言,我們計算它與手寫字H的相符性並令此值為 接下來我們要深入介紹Introduction中提到過的inter-feature
similarity 和 inter-link similarity計算方式.
假設我們今天要比對相對應的feature pairs
Train the network (J.13) 在我們的network中,我們將每一個收斂的state寫成一個矩陣V,
其中V的每一列(row)表示字根的features, 而V的每一行(column)表示手寫字的features.
並且當Vlm=1時,表示第l個字根的feature與第m個手寫字的feature相符,此時我們會把這對pair
我們可以把上述的要求限制寫成一個方程式,我們稱它作energy function:
|此三項滿足第一和二條的限制 ||此項滿足第三條的限制 | 其中A=500, B=500, C=500/N, D=500N/80, 且N=LjM. 而network的state會隨著下式作改變:
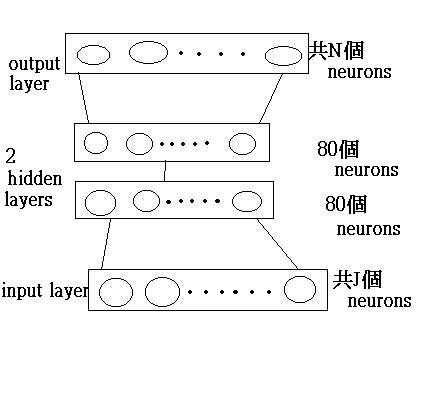
而對於Vlm的初始值而言,若 我們的network採用backpropogation的方式(因為簡單的classification對於中文字而言是不夠的),而network的架構為如下所示:
我們輸入之前求得的
|
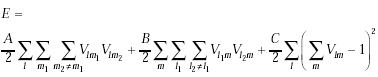
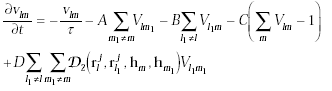 , 且
, 且